Cut down database imports by a third using this one weird trick
Our open-source bulk loader for PostgreSQL is faster than ever
Today the California Civic Data Coalition released a powerful improvement to its open-source tool for importing data via the Django web framework.
Version 2.2 of django-postgres-copy, now available on the Python Package Index, boosts the performance of PostgreSQL’s COPY command by automatically dropping indexes and constraints on tables prior to the loading.
The result is significantly faster ingestion. Our speed tests – using tens of millions of state records – found the change reduced load time of large tables by nearly one third.
After data are safely loaded, indexes and constraints are restored to the database.
Current users of django-postgres-copy can benefit simply by upgrading. No code changes are necessary.
If you’re unfamiliar with our library, all you have to do is hook our custom manager to your database model and loading from a comma-delimited file becomes this easy:
MyModel.objects.from_csv("/path/to/your/import.csv")Why we did it
This improvement was pioneered by James Gordon, the Coalition’s lead developer.
He drew instruction from PostgreSQL’s official documentation, which reads:
If you are loading a freshly created table, the fastest method is to create the table, bulk load the table’s data using COPY, then create any indexes needed for the table. Creating an index on pre-existing data is quicker than updating it incrementally as each row is loaded.
If you are adding large amounts of data to an existing table, it might be a win to drop the indexes, load the table, and then recreate the indexes.
Gordon’s code handles this task using rarely utilized, low-level tools in Django’s database manager.
What to expect
Our speed tests were conducted in a Jupyter Notebook now available on GitHub. There you can see Python’s timeit module load 41 million records from CAL-ACCESS, the state of California’s jumbled, dirty and difficult database tracking money in politics.
Each table was loaded three times with the indexes left in place, and then three times with all indexes dropped prior to loading.
The results were clear. Total load time dropped from 21 minutes and 9 seconds with indexes to just 14 minutes and 31 seconds without. That’s a decrease of 31%.
Closer examination of the results shows that the bigger the table, the larger the savings. The chart below compares table size with reductions in load time. As you can see, the biggest tables scored the biggest gains.
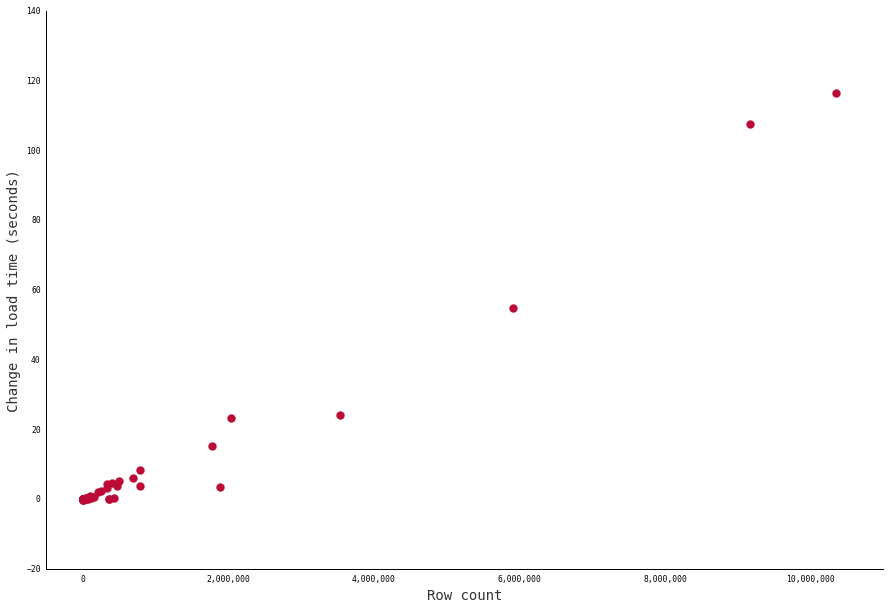
That said, not every table improved. Small tables sometimes saw a decrease in speed, likely due to the extra time needed to drop and restore the indexes. Our analysis found that gains were not guaranteed until tables approached 20,000 rows in length.
You can see that result in the next chart, which compares each table’s row count against its percentage change in load time. That puts more emphasis on shifts seen by smaller tables.
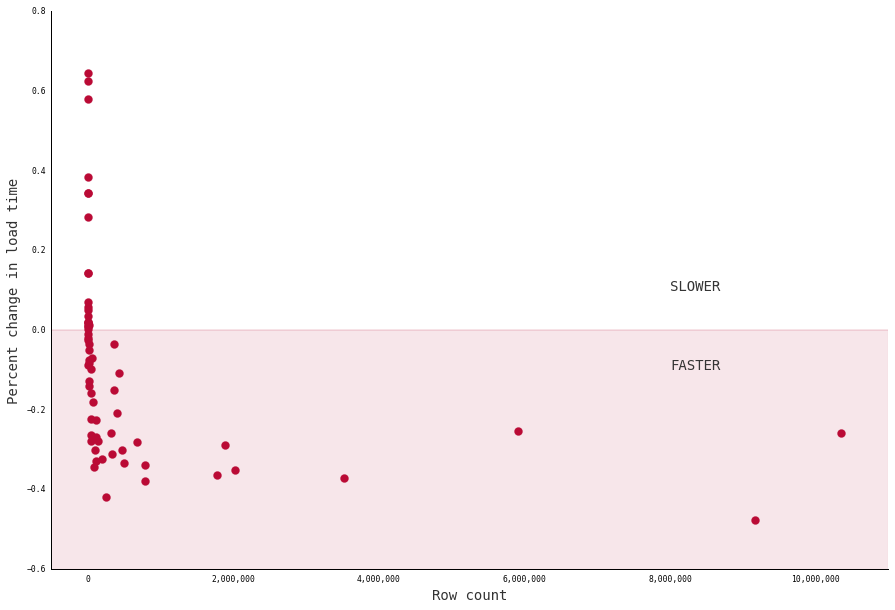
However, tables under 20,000 records loaded so quickly lags were negligible. And if you’d prefer to opt out of our new feature, you can always do so with the following keyword arguments:
MyModel.objects.from_csv(
"/path/to/your/import.csv",
drop_indexes=False,
drop_constraints=False
)As always, you mileage may vary. An obvious factor not tested here is the number and complexity of indexes and constraints on the database. Ours has two or three on most tables.
To learn more about how django-postgres-copy works, visit the technical documentation. There you’ll find a more complete explanation and information about tricks not covered here, like the recently-added ability to export tables.
Since django-postgres-copy was first released in 2015, it has drawn contributions from coders around the world, including some major improvements from users in other fields. If there are improvements you’d like to see, go get involved on our GitHub repository.